Applied Machine Learning Online Course
Category: AI & Machine LearningApplied Machine Learning Online Course
Category: AI & Machine LearningObective of Applied AI/ Machine Learning Online Course:
The AppliedAICourse attempts to teach students/course-participants some of the core ideas in machine learning, data science and AI that would help the participants go from a real-world business problem to a first cut, working and deployable AI solution to the problem.
Our primary focus is to help participants build real-world AI solutions using the skills they learn in this course. This course will focus on practical knowledge more than mathematical or theoretical rigor. That doesn't mean that we would water down the content. We will try and balance the theory and practice while giving more preference to the practical and applied aspects of AI as the course name suggests. Through the course, we will work on 15+ case studies of real-world AI problems and datasets to help students grasp the practical details of building AI solutions. For each idea/algorithm in AI, we would provide examples to provide the intuition and show how the idea to be used in the real world.
Key Points:
- 1. The validity of the Applied Machine Learning course is 365 days from the date of enrollment.
- 2. Expert Guidance, we will answer your queries in atmost 24hours.
- 3. 15+ real world case studies(includes 2 self case studies).
- 4. 30+ machine learning and Deep learning algorithms will be taught in this course.
- 5. There are no prerequisites for this course as we have taught everything from scratch including python programming.
- 6. We will also be conducting 70+ hours of live content based on students feedback and industry needs. We would cover topics to prepare our students better for real-world problem solving and interviews.
- 7. A mentor will be assigned to each candidate after the completion of 50% of the course assignments whose sole concentration would be on building the specific student's portfolio/resume and in interview preparation, mock interviews.
Target Audience:
Applied AI Course is designed to cater to the needs of students at various levels of expertise and varying background skills. Within the validity period of 365 days, students can complete the course anytime based on their feasibility and at their own pace. It will take 6 months to complete the course if you can put an effort of 14 to 15hrs per week. More the effort, better the results. Here is a list of candidates who would benefit from our course:- Undergrad (B.Tech/B.E/BSc statistics/Bsc computer science/BCA) students in engineering and science.
- Grad(MS/MTech/ME/MCA) students in engineering and science.
- Working professionals: Software engineers, Business analysts, Startup teams building ML products/services, Product managers, Program managers, Managers, etc.
- Data Analysts, Data Scientists, ML Scientists and ML engineers.
Course Features

QUALIFICATION: Masters from IISC Bangalore, PROFESSIONAL EXPERIENCE: 11+ years of Experience( Yahoo Labs, Matherix Labs Co-founder, and Amazon)
Applied Machine Learning Online Course
Category: AI & Machine Learning
2843 Comment(s)
Loading...
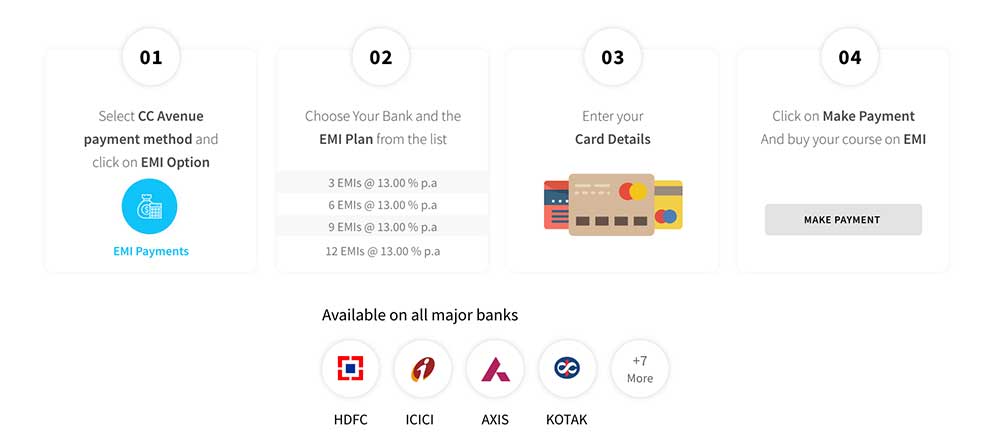
Pay easy monthly installments instead of lump-sum amount.