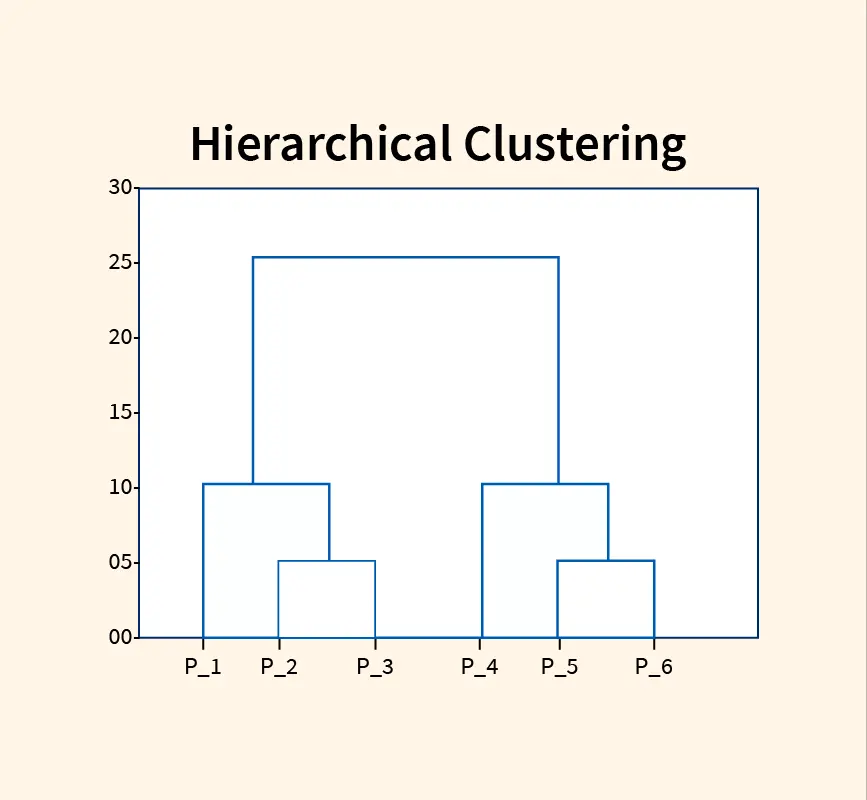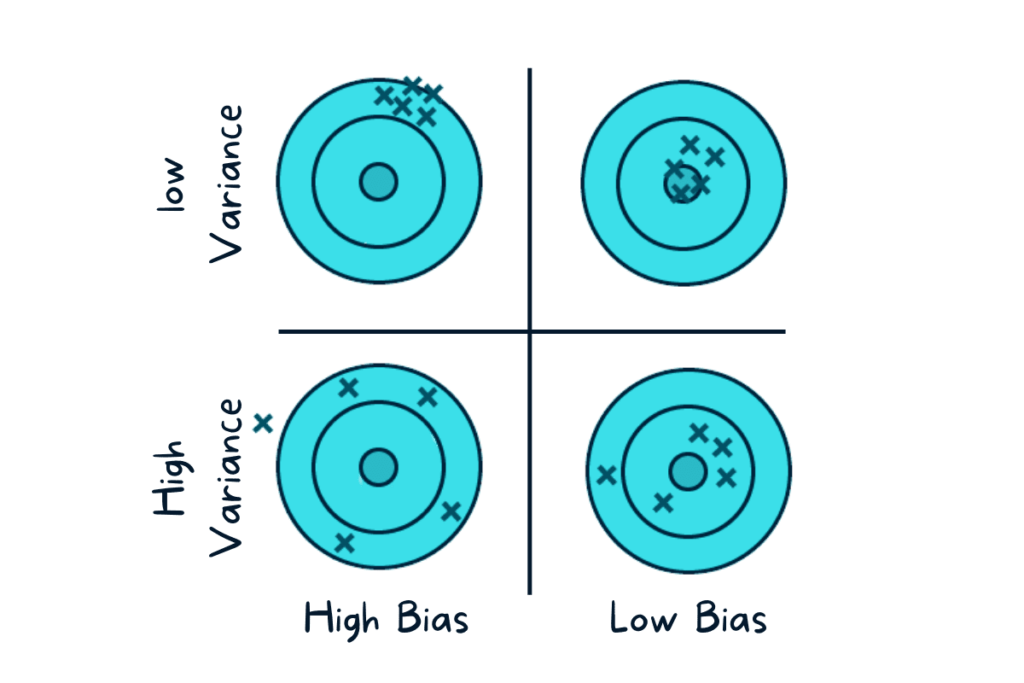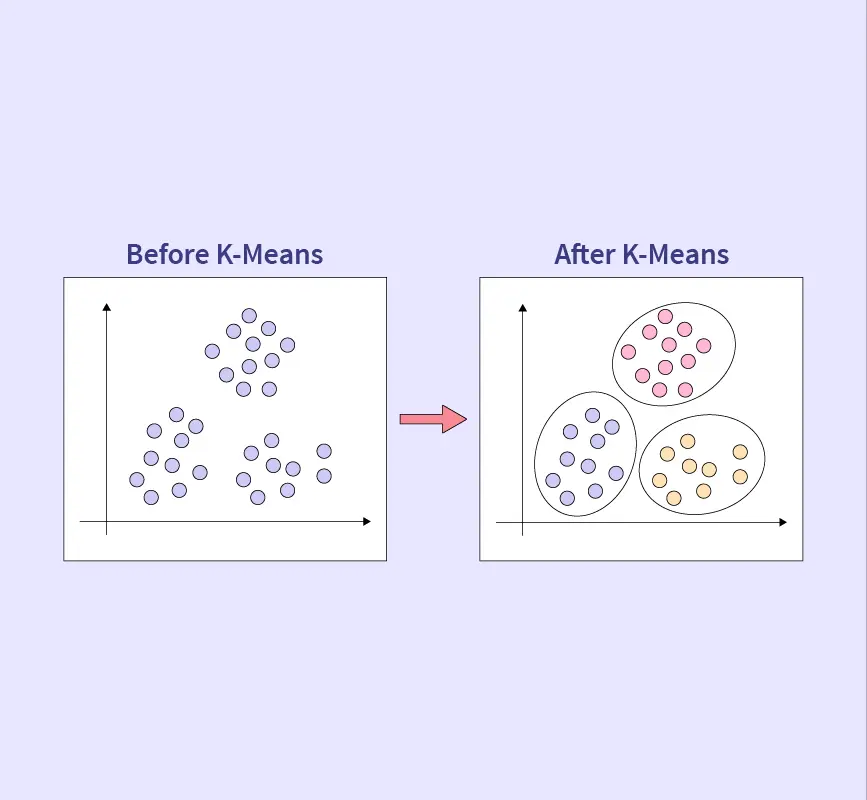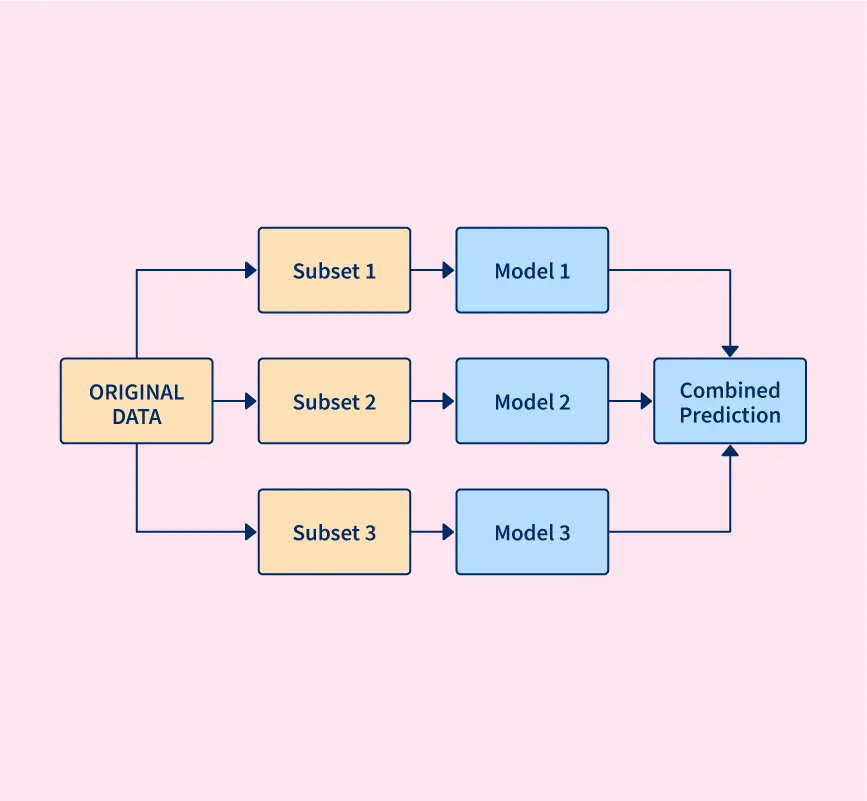
Feature Selection in Machine Learning
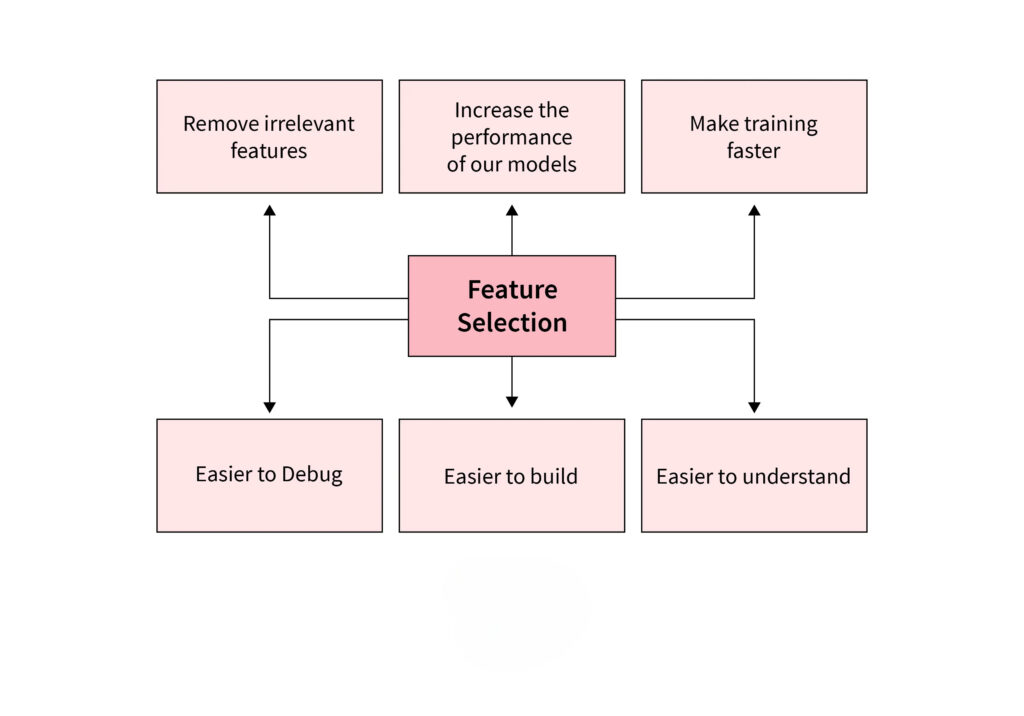
In machine learning, models rely heavily on the features of a dataset to make accurate predictions. However, more data does not always lead to better results. This is where feature selection becomes critical. It is a process that involves selecting a subset of the most relevant features, helping to improve model performance, reduce training time, ...