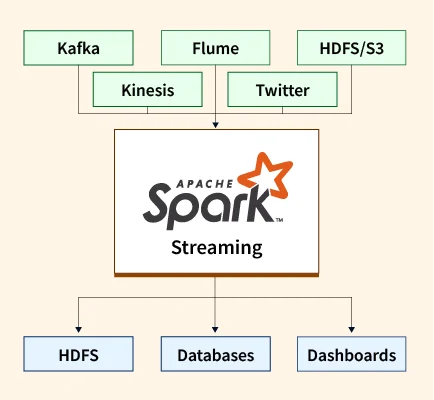
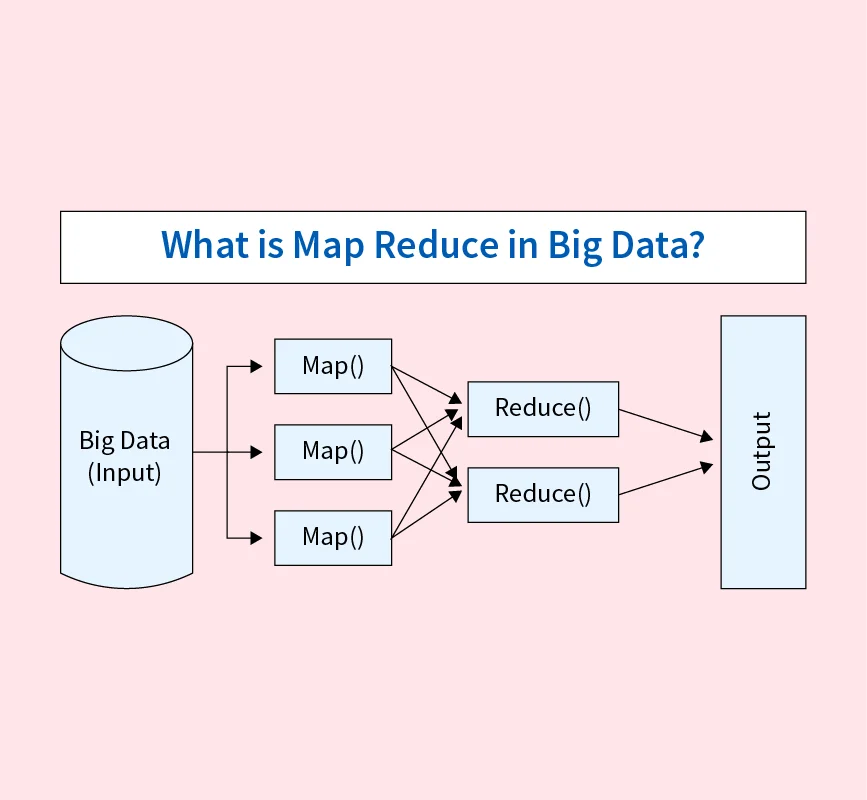
Hadoop Distributed File System (HDFS) — A Complete Guide
The explosion of big data in recent years created a critical need for scalable, distributed storage systems capable of handling massive datasets efficiently. Hadoop Distributed File System (HDFS) emerged as a powerful solution, offering a fault-tolerant, scalable way to store and manage big data across clusters of inexpensive, commodity hardware. What is HDFS? HDFS stands ...