Regularization is a critical technique in machine learning used to improve the performance of models by reducing overfitting. Overfitting occurs when a model learns too much from the training data, capturing noise and irrelevant patterns that hinder its ability to generalize to new data.
Regularization introduces a penalty term to the loss function, discouraging the model from becoming too complex. This penalty helps control model coefficients and reduces variance, ensuring better performance on unseen data. In essence, regularization strikes a balance between underfitting and overfitting, allowing for more robust and generalizable models.
The Role of Regularization in Machine Learning
Regularization is a technique to constrain or regularize the coefficients of a machine learning model, preventing it from fitting noise or irrelevant patterns in the data. It introduces a penalty term to the loss function, which discourages the model from assigning too much importance to any particular feature, thereby avoiding overfitting.
When a model is too complex, it may perform well on training data but poorly on unseen data. Regularization mitigates this by shrinking coefficients, leading to a simpler and more generalizable model.
Use Cases Where Regularization is Crucial
- High-dimensional datasets: When the number of features is larger than the number of samples.
- Models prone to overfitting, such as polynomial regression.
- Sparse datasets: Where only a few features are relevant, but the model needs to identify them effectively.
Regularization ensures the model remains efficient and generalizable, improving overall performance.
Understanding Overfitting and Underfitting
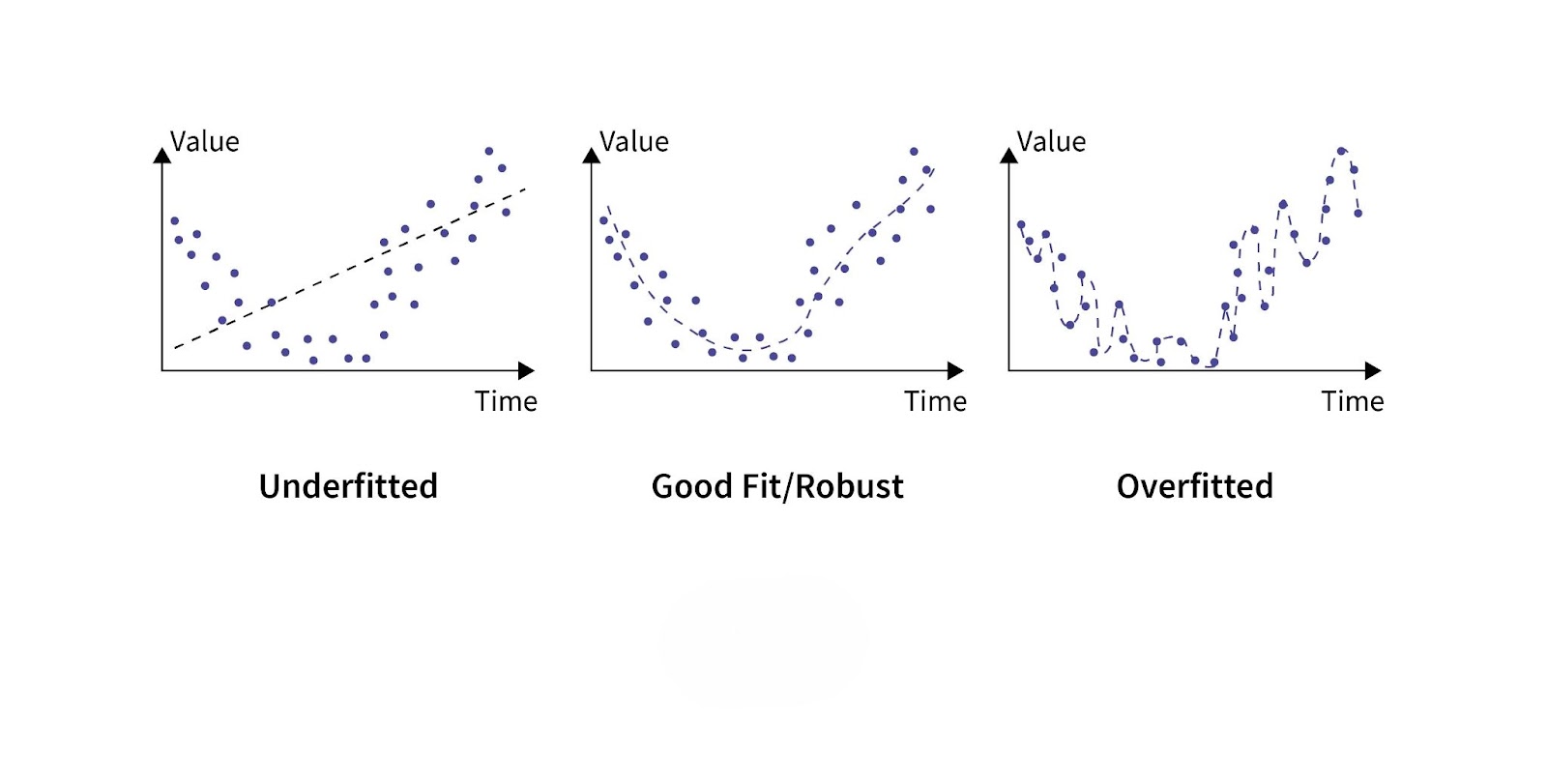
Overfitting
Overfitting occurs when a model learns too much detail and noise from the training data, capturing patterns that do not generalize to new data. For example, a complex model trained on a small dataset might achieve near-perfect accuracy on training data but perform poorly on test data.
Underfitting
Underfitting happens when the model is too simple to capture the underlying patterns in the data, leading to poor performance on both training and test datasets. For example, using linear regression to model a non-linear relationship will result in underfitting.
Balancing Bias and Variance
Overfitting corresponds to high variance—the model is too sensitive to training data. Underfitting corresponds to high bias—the model makes overly simplistic assumptions about the data.
Regularization is essential to strike a balance between bias and variance, helping the model achieve better generalization and optimal performance.
Bias-Variance Tradeoff
The bias-variance tradeoff is a fundamental concept in machine learning. Bias refers to the error introduced by approximating a real-world problem with a simplified model. Variance is the error due to the model’s sensitivity to small fluctuations in the training data.
- High bias models (e.g., linear regression) make strong assumptions and underfit the data.
- High variance models (e.g., deep neural networks) capture noise and overfit the data.
Regularization plays a vital role in managing this tradeoff by controlling model complexity. It reduces variance by penalizing large coefficients and encouraging the model to remain simpler and less sensitive to fluctuations in the data. By striking a balance, regularization allows the model to generalize better, improving performance on unseen data.
Techniques of Regularization
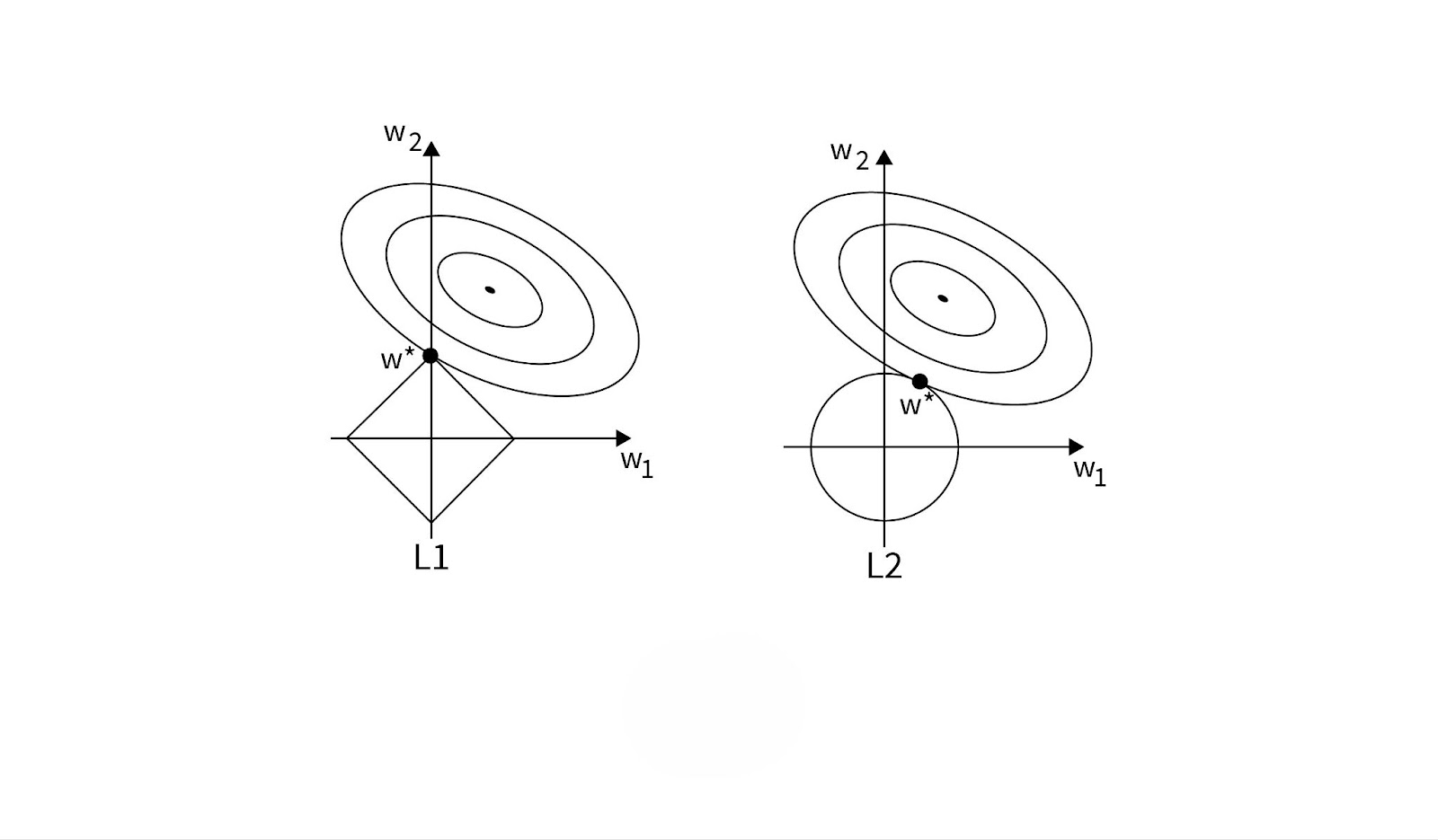
Regularization techniques are essential for managing model complexity and ensuring generalization to unseen data. Different methods target various challenges, such as large coefficients, overfitting, and feature selection. Below are key regularization approaches, each suited to specific scenarios in machine learning.
1. Ridge Regression (L2 Regularization)
Ridge regression, also known as L2 regularization, works by adding a penalty proportional to the square of the magnitude of the coefficients to the loss function. This penalty discourages the model from assigning large weights to any particular feature, helping it avoid overfitting.
The objective function for ridge regression is:
$$\text{Loss} = \sum (y_i – \hat{y_i})^2 + \lambda \sum w_j^2$$
Where:
- $y_i$ is the actual value
- $\hat{y_i}$ is the predicted value
- $w_j$ represents the coefficients
- $\lambda$ is the regularization parameter controlling the extent of penalization
When $\lambda = 0$, the model behaves like standard linear regression. As $\lambda$ increases, the magnitude of coefficients shrinks, improving generalization.
Use Cases:
- Ridge regression is effective when many features contribute to the prediction.
- It’s commonly used in high-dimensional datasets where multicollinearity is a concern.
2. Lasso Regression (L1 Regularization)
Lasso regression, or L1 regularization, adds a penalty proportional to the absolute value of the coefficients. Unlike ridge regression, lasso can shrink some coefficients to zero, making it an effective technique for feature selection.
The objective function for lasso regression is:
$$\text{Loss} = \sum (y_i – \hat{y_i})^2 + \lambda \sum |w_j|$$
This formulation forces the model to drop unnecessary features, simplifying the model while retaining only the most impactful variables.
Use Cases:
- Lasso is useful in scenarios where only a few features are relevant.
- It is often applied in sparse datasets or when feature selection is crucial to model interpretability.
However, lasso may struggle with datasets where highly correlated features exist, as it tends to select one feature and ignore others.
3. Elastic Net Regression
Elastic Net regression is a combination of L1 (lasso) and L2 (ridge) regularization, addressing the limitations of each method. It introduces a penalty term that blends both absolute values and squares of coefficients.
The objective function for elastic net is:
$$\text{Loss} = \sum (y_i – \hat{y_i})^2 + \lambda_1 \sum |w_j| + \lambda_2 \sum w_j^2$$
Elastic Net is particularly useful when the dataset contains highly correlated features, as it assigns weights more evenly than lasso alone.
When to Use Elastic Net:
- When the dataset has many correlated features.
- When a balance between feature selection and coefficient shrinkage is desired.
Elastic Net offers flexibility by tuning both L1 and L2 penalties, providing a balance between the advantages of ridge and lasso.
4. Dropout Regularization (for Neural Networks)
Dropout regularization is a technique used in neural networks to prevent overfitting. During training, dropout randomly deactivates a subset of neurons in each layer, forcing the network to learn more robust patterns and avoid reliance on specific neurons.
In practice, dropout introduces a probability $p$, which determines the proportion of neurons to be dropped during training. For instance, if $p = 0.5$, half the neurons in a given layer are ignored during a specific iteration.
Benefits of Dropout:
- It enhances the model’s ability to generalize by preventing co-adaptation of neurons.
- Dropout has been instrumental in the success of deep learning models, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs).
Dropout is applied during training, but the entire network is used during inference, ensuring optimal performance.
Key Differences between Ridge and Lasso Regression
| Aspect | Ridge Regression (L2) | Lasso Regression (L1) |
| Penalty | Sum of squared coefficients ($\sum w_j^2$) | Sum of absolute coefficients ($\sum |w_j|$) |
| Feature Selection | Retains all features with small weights | Shrinks some coefficients to zero, performing feature selection |
| Handling Multicollinearity | Effective in managing correlated features | Selects one feature and discards others in correlated sets |
| Use Case | Suitable for models with many predictors | Best for sparse datasets where feature selection is needed |
| Interpretability | Less interpretable, as all features are retained | More interpretable due to zeroed-out coefficients |
Benefits and Limitations of Regularization
Benefits
- Prevents Overfitting: Regularization ensures the model generalizes better to unseen data.
- Feature Selection: Lasso regularization identifies the most impactful features by reducing irrelevant coefficients to zero.
- Improves Interpretability: Models become easier to interpret when unnecessary features are excluded.
Limitations
- Parameter Tuning: Choosing the right regularization parameter ($\lambda$) requires trial and error.
- Limited in Non-Linear Models: Standard regularization methods may not be sufficient for complex non-linear relationships.
- Risk of Underfitting: Over-penalizing coefficients can lead to underfitting, reducing the model’s performance.
Conclusion
Regularization plays a pivotal role in machine learning by balancing model complexity and performance, ensuring better generalization. Choosing the right regularization technique depends on the data, feature set, and task requirements. Understanding when to use ridge, lasso, or other methods is essential for building effective models.
References:
- What Is Regularization? | IBM
- A Comprehensive Guide to Regularization in Machine Learning | by Juan C Olamendy | Medium


