Clustering is a fundamental task in machine learning, involving the grouping of similar data points. Density-based clustering methods, like DBSCAN (Density-Based Spatial Clustering of Applications with Noise), are highly effective for identifying clusters in noisy datasets. Unlike centroid-based methods, DBSCAN forms clusters based on data point density, making it suitable for datasets with arbitrary shapes.
DBSCAN is particularly useful in anomaly detection and spatial data analysis, where outliers must be identified. This method offers robust performance by detecting clusters with varying densities, making it an essential tool for unsupervised learning tasks in diverse fields.
What is DBSCAN?
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is a clustering algorithm that groups data points based on density, making it ideal for detecting clusters of arbitrary shapes. Unlike centroid-based clustering algorithms, such as K-Means, DBSCAN doesn’t require specifying the number of clusters in advance. It also identifies outliers as noise, which makes it robust for datasets with anomalies.
Key Features of DBSCAN
- Noise Handling: DBSCAN efficiently identifies outliers that do not belong to any cluster.
- Cluster Detection with Varying Densities: The algorithm can detect clusters with different densities, unlike K-Means, which assumes clusters are spherical.
Applicability in Real-World Scenarios
DBSCAN finds applications in anomaly detection (e.g., fraud detection) and spatial data analysis (e.g., geographic mapping). It’s particularly effective in geospatial datasets or datasets with non-uniform cluster shapes, where traditional algorithms like K-Means may fail to perform well.
Parameters of the DBSCAN Algorithm
DBSCAN relies on two primary parameters to detect clusters: Epsilon (ε) and MinPts.
Epsilon (ε)
Epsilon defines the maximum radius within which neighboring points are considered part of the same cluster. A smaller ε results in more clusters with fewer points, while a larger ε may group more points into larger clusters. Choosing an appropriate ε is crucial to balancing cluster granularity and performance.
MinPts
MinPts specifies the minimum number of points required to form a dense region, which defines the core of a cluster. Higher MinPts values result in fewer clusters, but they are more robust to noise. Lower values may generate more, smaller clusters.
Influence of Parameters on Cluster Formation
Both ε and MinPts directly affect how clusters are detected. Setting these parameters correctly ensures DBSCAN’s effectiveness in identifying meaningful clusters and handling noise within the data.
Steps and Pseudocode for the DBSCAN Algorithm
- Select a Random Point: Begin with an unvisited point from the dataset.
- Identify Neighboring Points: Check if the number of points within the Epsilon (ε) radius meets the MinPts requirement.
- If yes, mark it as a core point and form a new cluster.
- If no, label the point as a noise point (though it might later belong to a cluster).
- Expand the Cluster: For each core point, expand the cluster by visiting neighboring points within the ε radius.
- Classify Border Points: Points within ε but without sufficient neighbors are border points and belong to the nearest cluster.
- Repeat: Continue until all points are visited and assigned to a cluster or marked as noise.
Pseudocode for DBSCAN
for each unvisited point P:
mark P as visited
neighbors = find_neighbors(P, epsilon)
if len(neighbors) < MinPts:
label P as noise
else:
create new cluster
expand_cluster(P, neighbors, epsilon, MinPts)Visual Example of Core, Border, and Noise Points
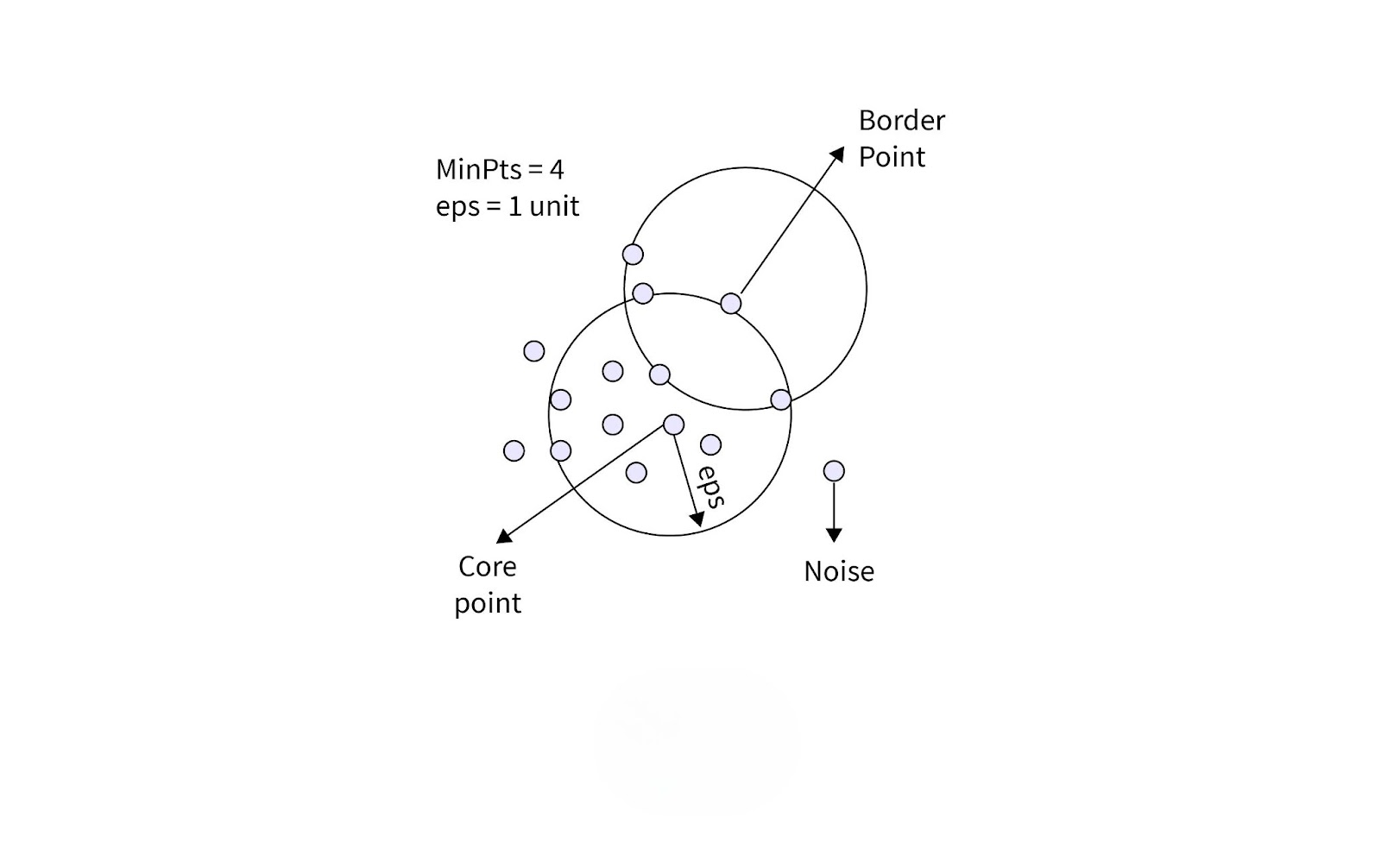
- Core Points: Have at least MinPts neighbors within ε radius.
- Border Points: Have fewer than MinPts neighbors but are close to a core point.
- Noise Points: Isolated points that don’t belong to any cluster.
This structure ensures DBSCAN accurately detects clusters and outliers without requiring a predefined number of clusters.
Implementing DBSCAN in Python Using Scikit-Learn
Step 1: Import Libraries and Load Data
To implement DBSCAN, we use scikit-learn, matplotlib, and NumPy. Below is the code to import the necessary libraries and load a sample dataset.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moonsWe’ll use the make_moons dataset, which has a non-linear structure, to showcase DBSCAN’s clustering capabilities.
X, y = make_moons(n_samples=300, noise=0.1)
plt.scatter(X[:, 0], X[:, 1])
plt.show()Step 2: Setting Parameters and Applying DBSCAN
We need to carefully choose the Epsilon (ε) and MinPts values. Here’s how we apply DBSCAN using scikit-learn:
dbscan = DBSCAN(eps=0.2, min_samples=5)
dbscan.fit(X)
labels = dbscan.labels_- eps defines the radius within which neighboring points are considered part of the cluster.
- min_samples sets the minimum number of points required to form a dense region.
After applying DBSCAN, the labels_ attribute contains the cluster assignments for each data point, with -1 indicating noise points.
Step 3: Visualizing Clusters
We can use matplotlib to visualize the identified clusters and noise points.
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.title('DBSCAN Clustering')
plt.show()Each color in the scatter plot represents a different cluster, and noise points are shown with a unique color or marker.
Step 4: Evaluating DBSCAN Performance
We can use evaluation metrics like silhouette score to assess clustering performance.
from sklearn.metrics import silhouette_score
score = silhouette_score(X, labels)
print(f'Silhouette Score: {score}')- Silhouette Score: Measures how well-separated the clusters are.
- Cluster Count: The number of clusters detected.
- Noise Percentage: Proportion of points classified as noise.
These metrics help ensure the DBSCAN model is properly configured to balance cluster detection and outlier identification.
DBSCAN vs. K-Means Clustering: When to Use DBSCAN
DBSCAN and K-Means differ significantly in their approaches to clustering. K-Means requires the number of clusters to be predefined, while DBSCAN determines the clusters based on data density. K-Means uses centroids to form spherical clusters, making it less effective for non-linear datasets, whereas DBSCAN identifies clusters of arbitrary shapes.
Handling Noise and Outliers
DBSCAN can identify noise points and outliers, while K-Means assigns every point to a cluster. This makes DBSCAN preferable in noisy datasets or when outlier detection is necessary.
Use Cases for DBSCAN
DBSCAN excels in datasets where clusters have varying densities or non-linear boundaries, such as geospatial data or anomaly detection tasks. In contrast, K-Means is more suitable for large datasets with well-separated clusters.
Selecting the Right Algorithm
DBSCAN should be chosen when cluster shapes vary or noise handling is essential. K-Means may be more appropriate for high-dimensional data or when a specific number of clusters is required.
Advantages and Limitations of DBSCAN
Advantages
- Handling Noise: DBSCAN can identify and isolate noise points without assigning them to a cluster.
- Arbitrarily Shaped Clusters: It effectively detects clusters with non-linear and irregular boundaries.
- Robust to Outliers: DBSCAN can manage datasets with outliers, ensuring the quality of clustering.
Limitations
- Parameter Sensitivity: The Epsilon (ε) and MinPts parameters require careful tuning, as inappropriate values can lead to poor clustering.
- Challenges with High-Dimensional Data: DBSCAN struggles with high-dimensional datasets because the density of points becomes harder to define in multiple dimensions.
- Performance Issues with Large Datasets: DBSCAN may not perform well with extremely large datasets, as the neighbor-search algorithm becomes computationally expensive.
DBSCAN is most effective for low-dimensional data with non-linear clusters and noise, but it may not be the best choice for high-dimensional or very large datasets.
Conclusion
DBSCAN is a powerful density-based clustering algorithm that identifies clusters of varying shapes and handles noise effectively. Its adaptability makes it useful for anomaly detection and spatial data analysis. However, parameter tuning is essential to achieve optimal results, ensuring meaningful clusters and avoiding poor model performance.
References:
- DBSCAN Clustering Algorithm in Machine Learning – KDnuggets
- Clustering Like a Pro: A Beginner’s Guide to DBSCAN | by Sachinsoni | Medium


