A guide to an efficient way to build neural network architectures- Part II
This article is a continuation to the article linked below which deals with the need for hyper-parameter optimization and how to do hyper-parameter selection and optimization using Hyperas for Dense Neural Networks (Multi-Layer Perceptrons)
In the current article we will continue from where we left off in part-I and would try to solve the same problem, the image classification task of the Fashion-MNIST data-set using Convolutional Neural Networks(CNN).
Why CNNs?
The CNNs have several different filters/kernels consisting of trainable parameters which can convolve on a given image spatially to detect features like edges and shapes. These high number of filters essentially learn to capture spatial features from the image based on the learned weights through back propagation and stacked layers of filters can be used to detect complex spatial shapes from the spatial features at every subsequent level. Hence they can successfully boil down a given image into a highly abstracted representation which is easy for predicting.
In Dense networks we try to find patterns in pixel values given as input for eg. if pixel number 25 and 26 are greater than a certain value it might belong to a certain class and a few complex variations of the same. This might easily fail if we can have objects anywhere in the image and not necessarily centered like in the MNIST or to a certain extent also in the Fashion-MNIST data.
RNNs on the other hand find sequences in data and an edge or a shape too can be thought of as a sequence of pixel values but the problem lies in the fact that they have only a single weight matrix which is used by all the recurrent units which does not help in finding many spatial features and shapes. Whereas a CNN can have multiple kernels/filters in a layer enabling them to find many features and build upon that to form shapes every subsequent layer. RNNs would require a lot of layers and hell lot of time to mimic the same as they can find only few sequences at a single layer.
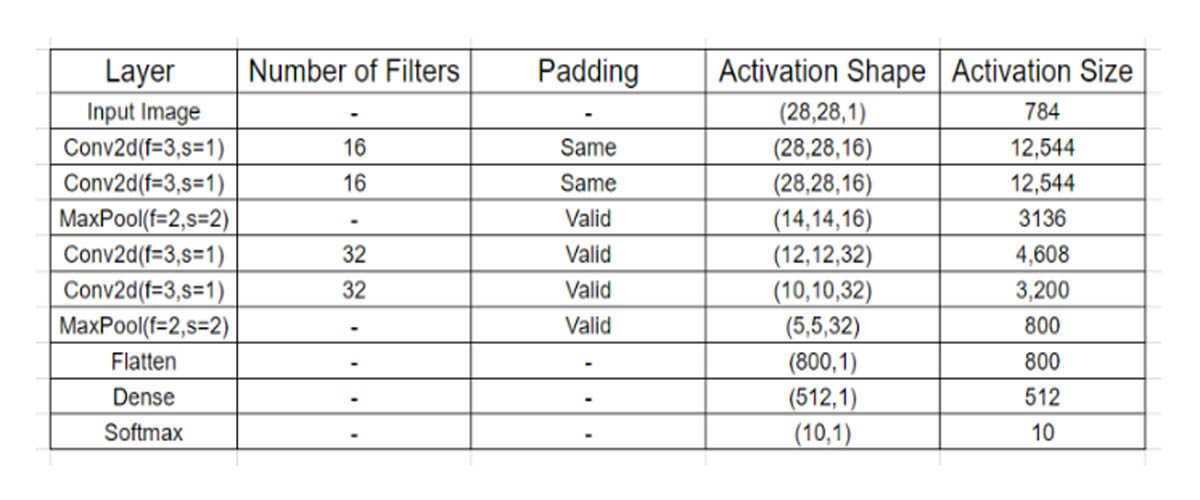
So lets take our quest forward with convolutional networks and see how well could a deeper hyper-parameter optimized version of this do, but before that lets have a look at the additional hyper-parameters in a convolutional neural net.