Deep learning model that can recognize the voice of a artist

Speaker recognition is the identification of a person from characteristics of his/her voice is an important human trait most take for granted in natural human-to-human interaction/communication. It is also called voice recognition. There is a difference between speaker recognition (recognizing who is speaking) and speech recognition (recognizing what is being said). These two terms are frequently confused, and “voice recognition” can be used for both[for more details].
Goal : Building a deep learning model that can recognize the voice of a artist(also known as dynamic voice identifer)for a given song with minimal training data.
Github Link : https://github.com/Hina19/Whos-The-Songster-
Overview : To create such a system, naturally the tool of choice would be an image classifier. Basically, this is the high level view of what i am going to do in building this recognition task.
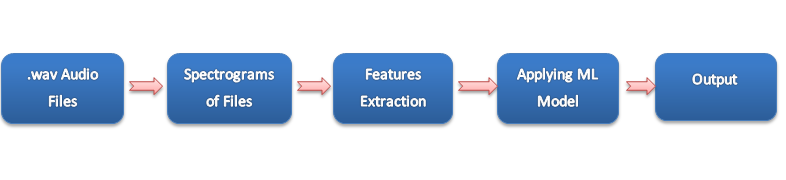
So, in the first step i am going to collect the audio files of different songsters(artists) in .wav format and then convert all audio files into a particular spectrogram(image representation) and after that extract features from images using CNN and then apply ML ensemble model gradient descent boosting.
Read about complete article here